The Star Schema Data Model For Modern Analytics

Waiting weeks for a data analyst to build a simple dashboard is a relic of the past. You have mountains of valuable data, but getting clear answers feels impossible. The good news? The problem isn't your data; it's how that data is organized. This is exactly what the star schema data model is designed to fix—and it’s the secret to getting fast, reliable insights.
Your Data Has Answers, But You Can't Get to Them
You're sitting on a goldmine. All the information about customer behavior, sales trends, and marketing performance is locked away in your databases. But when you need a straightforward chart, it turns into a formal request that lands in a queue, sometimes for weeks.

This delay isn’t happening because your analysts are slow. It’s because the underlying data is a tangled mess. When data is scattered across dozens of tables with no intuitive structure, every single question requires a complex, custom-built SQL query. It's a manual process that’s not only slow but also ripe for errors—a huge bottleneck for any company that needs to move quickly.
The Problem Is Structure, Not Your Data
A star schema cuts through this chaos. Think of it as a clean, logical blueprint for your business metrics. Instead of a web of interconnected tables that only a handful of experts can navigate, you get a simple, star-shaped model that makes finding information incredibly efficient.
This model has become the go-to standard for analytics for a few key reasons:
Speed: It’s optimized for lightning-fast queries.
Clarity: The structure is simple enough for both BI tools and humans to easily understand.
Reliability: It establishes a single source of truth for your most important metrics, ensuring everyone is looking at the same numbers.
Better yet, this clean structure is precisely what tools like a Conversational AI Data Analyst need to function. With a star schema in place, a platform like Statspresso knows exactly where to find the data to answer your questions instantly.
You can finally skip the SQL. Just ask a question, and get a chart in seconds.
This guide will walk you through why this simple-yet-powerful concept is the key to unlocking instant, trustworthy answers. We'll show you how to move from data chaos to a clean, effective model that empowers your entire team to make decisions without waiting in line.
Try asking Statspresso: "Show me my revenue by month for the last year as a bar chart."
What Is a Star Schema Data Model?
If you want to get real answers from your data, you first need to organize it in a way that makes sense.That's where the star schema comes in—it's less a technical command and more a brilliantly simple blueprint for your analytics. To see the full landscape, it's worth knowing how it fits into the broader world of data modeling and its various types.
Think of a star schema like this: at the very center, you have a single table holding all your most important numbers. This is your fact table. It contains the raw, quantitative metrics you're obsessed with tracking, like sales_revenue, units_sold, or user_signups. These are the "what happened" figures.
The Star Points: Context Is Everything
Of course, numbers without context are meaningless. Radiating out from that central fact table are several dimension tables, which form the points of the star. These tables provide the crucial "who, what, where, and when" that give your facts meaning.
Each dimension table is dedicated to describing one business concept:
Customers: Who made the purchase?
Products: What exactly did they buy?
Locations: Where did this transaction take place?
Dates: When did it all happen?
This "hub-and-spoke" design is the star schema's superpower. When you need an answer, you simply connect the context from a dimension table (a spoke) to the numbers in the central fact table (the hub). This structure dramatically reduces the complex "joins" that slow traditional databases to a crawl, making your queries incredibly fast.
This isn't some new trend; the star schema has been a fundamental part of data warehousing since the 1990s. Its elegant simplicity is why it delivers lightning-fast queries, giving it a massive performance edge over more complicated models. That speed is more critical than ever, especially as AI-driven demands for quick data access continue to grow. You can find more on how the star schema compares to other models on Kanerika.com.
Why This Matters for You
So, why should a founder or product manager care about data architecture? Because a well-designed star schema is the bedrock of self-service analytics and a single source of truth everyone in the company can rely on.
Even more importantly, this clean structure is what enables a Conversational AI Data Analyst, like Statspresso, to understand your business. The AI can instantly see the relationship between customers and sales because the star schema acts as a clear, logical map. You just ask, and the AI follows the paths on the map to pull your answer.
Instead of waiting for a developer to write a complex SQL query, you simply connect the dots. It’s analytics at the speed of thought.
The difference in workflow is night and day. The old, manual process is a bottleneck; the new way is instantaneous.
Old Way (Manual SQL & Dashboards) | New Way (Statspresso & Star Schema) |
|---|---|
Wait days or weeks for a report | Get answers in seconds |
Relies on technical experts | Empowers anyone to ask questions |
Complex, error-prone queries | Direct, plain-English questions |
Static, quickly outdated reports | Real-time, interactive charts |
By organizing your data this way, you shift from being reactive to proactive. Your data stops being a frustrating roadblock and becomes your most powerful strategic asset.
The Building Blocks of a Star Schema
Alright, so you see the appeal of the star schema. But what are the actual moving parts? It's less complicated than you might imagine. A star schema is built from just two core components: fact tables and dimension tables.
Think of it like building with LEGOs. You have your core structural bricks and your specialized, descriptive pieces. Getting these two parts right is everything. In fact, knowing how to design database schema for scalable applications is a foundational skill for anyone building a data model that needs to stand the test of time and scale.
The Center of the Universe: The Fact Table
First, let's talk about the fact table. This is the sun in your solar system—the gravitational center holding everything together. It's where you store the quantitative pulse of your business: the raw numbers and metrics you track. Think sales_amount, units_sold, login_count, or ad_spend.
Essentially, these tables are just a running log of business events. Every time a customer completes a purchase or a user views a page, a new row is added to a fact table. The key thing to remember is that facts are numeric and measurable. You can add them, average them, or count them. You can't sum up customer names, but you can absolutely sum up their lifetime value.
This brings us to a crucial concept: granularity. The grain of your fact table defines the level of detail each row represents. Is a single row one transaction? One item within a transaction? Or a daily summary of all sales for a store?
Choosing the right grain is the single most important decision you'll make when designing a star schema. It dictates the kinds of questions you can answer. If your grain is "daily sales per store," you can never analyze sales by the hour.
The Points of the Star: Dimension Tables
A fact table full of numbers is pretty useless on its own. 100,000 means nothing without context. That’s where dimension tables shine. They are the descriptive tables that orbit your central fact table, providing the all-important "who, what, where, when, and why" behind your metrics.
Some classic examples of dimension tables include:
dim_Customers: Who made the purchase? This table holds customer names, locations, segments, and sign-up dates.
dim_Products: What was purchased? Here you'll find the product name, category, brand, color, and size.
dim_Date: When did it happen? This is a special but essential table that breaks down dates into useful attributes like year, quarter, month, day of the week, and holiday flags for powerful time-based analysis.
This simple diagram perfectly captures the relationship. The central fact table gives you the numbers, and the surrounding dimension tables tell you the story behind them.
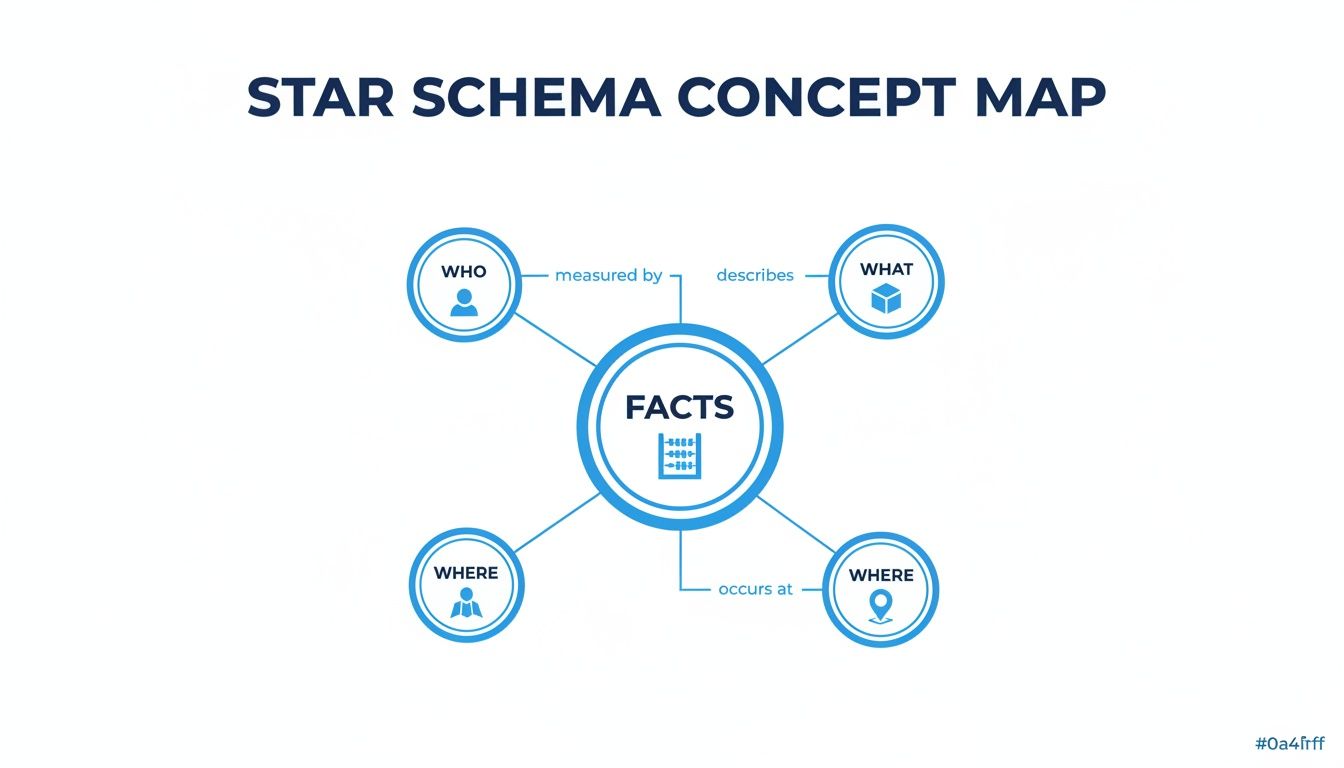
As you can see, you get answers by connecting the context (the Who, What, Where) to the core events (the Facts). This structure makes slicing and dicing your data incredibly intuitive.
The Glue That Holds It Together: Keys
So how do we physically link the fct_Sales table to the dim_Products table? We use keys. Keys are just special columns that serve as unique identifiers, forming the connective tissue between your facts and dimensions.
In the world of data modeling, you'll mainly encounter two types of keys:
Natural Keys: These are identifiers that already exist in your operational systems. Think of a product's SKU, a user's email address, or a government ID number. They seem convenient at first but can be a trap. What happens when an email changes or a SKU is recycled? Chaos.
Surrogate Keys: These are clean, system-generated integers (e.g., 1, 2, 3...) that have no business meaning whatsoever. Their only job is to uniquely identify a row in a dimension table within the data warehouse.
When it comes to analytics, surrogate keys are almost always the better choice. They’re stable even when business attributes change, they're small, and they make the joins between your potentially massive fact table and your dimensions incredibly fast. This is the kind of clean, efficient design that allows a Conversational AI Data Analyst like Statspresso to zip through your data and find answers in seconds.
Star Schema vs. Snowflake Schema: A Quick Comparison
If you've spent any time around data warehouses, you've probably heard the term "snowflake schema" pop up. It’s often mentioned in the same breath as the star schema, but don't be fooled—the two models are built for very different purposes, and choosing the wrong one can bring your analytics to a grinding halt.
At their core, the difference comes down to one concept: denormalization. A star schema embraces it. It keeps all the related details for a business concept—like a product's name, its category, and its brand—together in a single, wide dimension table. It’s simple and straightforward.
A snowflake schema does the opposite. It normalizes those dimensions, breaking them out into a web of smaller, interconnected tables. You might have a product table that links to a separate category table, which then links to yet another sub-category table. This creates a structure with many intricate, branching points, much like a snowflake.
It All Comes Down to Performance
The main argument for the snowflake schema is that it can save a little bit of storage space by reducing redundant data. While true in theory, this tiny bit of savings comes at a massive cost: query performance.
Every extra table in a snowflake schema adds another JOIN operation to your query. More joins mean more work for the database, which leads to slower queries. For anyone who needs to make decisions quickly, waiting minutes for a dashboard to load simply isn't an option. The star schema’s flat, simple structure is built for speed, making it the clear winner for modern analytics.
For the vast majority of BI and analytics tasks—we’re talking over 90% of cases—the star schema’s incredible speed and simplicity make it the superior choice.
Star Schema vs. Snowflake Schema: Which Is Right for You?
While snowflake schemas still have a place in some highly specialized, transaction-heavy enterprise systems, the star schema is almost always the right answer for fast, reliable analytics. Let's put them side-by-side to see why. This table compares the two popular data modeling schemas across key attributes to help you decide which is better for your analytics needs.
Attribute | Star Schema (Optimized for Speed) | Snowflake Schema (Optimized for Storage) |
|---|---|---|
Query Speed | Lightning-fast. Fewer joins mean queries run in a fraction of the time, keeping dashboards responsive. | Slower. Requires multiple, complex joins that can easily bog down performance. |
Complexity | Low. The model is intuitive and easy for both humans and BI tools to understand and navigate. | High. The web of interconnected tables is confusing for anyone who isn't a data engineer. |
Ease of Use | Effortless. The simple structure is ideal for BI tools and AI assistants that need to interpret the data. | Difficult. Writing SQL is more complex, and business users will struggle to make sense of the model. |
Maintenance | Simpler to manage. The straightforward design is easier to troubleshoot and maintain as a single source of truth. | More complex to maintain. While updating a single attribute is easy, managing the entire structure is not. |
For most modern BI and AI analytics, the star schema's performance is superior. The decision really hinges on what you value most: a small amount of storage efficiency or real-world, practical speed. The star schema is purpose-built to get you answers fast. It’s the pragmatic choice for teams that need to move quickly and make decisions with fresh data, not wait around for a complex query to finish.
This focus on speed is exactly why tools like Statspresso are designed to work seamlessly with star schemas.
Try asking Statspresso: "Compare our top 5 products by total sales this quarter."
Why Conversational AI Loves the Star Schema
So, why does the star schema get so much attention? It's pretty straightforward: this particular data model is the backbone that allows modern analytics tools to deliver answers so quickly. More to the point, it’s what lets a Conversational AI Data Analyst like Statspresso respond to your questions in seconds, not weeks.

The star schema’s popularity isn't an accident; it’s a direct result of its effectiveness. It has become a de-facto standard for a reason. And with Gartner predicting that by 2026, 70% of organizations will focus on business outcomes by adopting vertically integrated data stacks, the need for a simple, fast, and understandable data model like the star schema will only grow. This widespread adoption means that no matter what tool you're using—Tableau, Power BI, or a next-generation platform—the system can intuitively understand your data’s layout. You can explore the full research on modern data trends to see how it fits into the broader landscape.
Eliminating Ambiguity for the AI
Think about onboarding a new analyst. If you just pointed them to a messy collection of spreadsheets and asked for a sales comparison, they’d immediately have questions. "Which sales numbers? For what time period? How do I connect products to regions?" An AI runs into the exact same wall of confusion.
The star schema gets rid of all that ambiguity by providing a clean, pre-defined map of your business logic.
Facts are unmistakable: The AI knows that the
fct_salestable holds your core quantitative metrics, like revenue or units sold.Dimensions add context: It sees
dim_productanddim_regionand instantly grasps that these tables describe the "what" and "where" behind the numbers.Relationships are crystal clear: The keys connecting the tables act like well-lit signposts, telling the AI exactly how to join sales events with the products sold and the regions they were sold in.
So when you ask a question like, "Compare sales for Product A and Product B by region this quarter," the AI isn't left to guess. It’s simply following the logical pathways you’ve already built into the model.
A star schema transforms a complex guessing game into a simple game of connect-the-dots. The AI doesn’t have to waste processing power figuring out your data's structure; it can get straight to calculating the answer.
The Power of Speed and Simplicity
The real magic happens when you pair this predictable structure with a powerful conversational AI engine. The star schema provides the clean, high-octane fuel, and the AI acts as the high-performance engine that runs on it.
This is exactly why you can skip writing SQL and just ask your data a question. Behind the scenes, the AI translates your plain-English request into an incredibly efficient SQL query. Because the star schema’s structure is so logical, the resulting query is simple, with very few joins needed to get the job done fast.
This stands in stark contrast to a snowflake schema, which can slow down queries by 2-5x due to the chain of extra joins required to piece together information. For the dashboards and self-serve reports that inform an estimated 80% of business decisions, the star schema’s speed is a crucial advantage.
Let's look at how this changes the day-to-day workflow.
The Old Way (Manual SQL & Traditional BI) | The New Way (Statspresso & Star Schema) |
|---|---|
Your question becomes a ticket in a backlog. | You ask your question directly in plain English. |
An analyst deciphers a messy data structure. | The AI instantly maps your words to facts and dimensions. |
They write a complex, multi-join SQL query. | The AI generates a simple, optimized SQL query. |
You get a static report back days or weeks later. | You get an interactive chart back in seconds. |
This partnership between a well-designed star schema data model and a conversational platform creates true self-service analytics. It finally closes the gap between having data and actually being able to use it. The growth of AI-powered business intelligence is built on this very foundation.
Try asking Statspresso: "Show me my top 10 customers by lifetime value as a horizontal bar chart."
Key Takeaways: Your Star Schema Cheat Sheet
You're busy. Here's the TL;DR on the star schema data model so you can get back to building your business.
It’s a Blueprint for Speed: The star schema organizes your data for one thing: fast, simple queries.
Facts in the Middle, Context on the Sides: It uses a central fact table for your numbers (like revenue) and surrounding dimension tables for context (like customers, products, and dates).
Fewer Joins = Faster Answers: The flat structure avoids the complex, multi-step queries that slow down other models, making it ideal for analytics.
The AI's Best Friend: This clear, logical layout is exactly what a Conversational AI Data Analyst like Statspresso needs to understand your data and answer questions instantly.
The Goal is Self-Service: The ultimate benefit is empowering your whole team to skip the SQL, ask questions in plain English, and get charts in seconds.
Frequently Asked Questions
Do I Need to Be a Data Engineer to Build a Star Schema?
Not like you used to. While a data engineer is still the best person for a massive, enterprise-wide implementation, modern tools have made star schemas much more accessible.
Platforms like dbt (data build tool) let analysts with some SQL knowledge transform raw data from sources like Postgres or Shopify into clean star schemas. And for those who aren't technical, a conversational AI platform like Statspresso works best with a star schema, but it's often smart enough to make sense of less-structured data, too.
Can I Use a Star Schema with Real-Time Data?
Absolutely, though with a couple of things to keep in mind. Star schemas earned their reputation in data warehouses that were updated in batches overnight. But today, they work perfectly well for near real-time analytics.
Modern cloud data warehouses like Snowflake or BigQuery and new streaming technologies let you update your fact tables in tiny, frequent micro-batches. For most business questions, a few minutes of delay is perfectly fine, and the sheer query speed of the star schema makes it the right choice.
Try asking Statspresso: "Show me our sales from the last hour, broken down by product category."
How Many Dimension Tables Are Too Many?
There isn't a magic number. A typical star schema data model might have anywhere from five to fifteen dimension tables. The real question to ask yourself is: what context do I need for my analysis?
If you need to slice your key numbers by a business concept—like a customer segment, a marketing campaign, or a sales region—then it probably deserves its own dimension table. The goal isn't to hit a certain number; it's to keep the model simple and clear so you can get fast, intuitive answers.
Ready to stop waiting for reports and start getting answers? With Statspresso, you can skip the SQL and the dashboard queues. Just ask your data a question and get a chart in seconds.
Connect your first data source for free and ask your first question.
Waiting weeks for a data analyst to build a simple dashboard is a relic of the past. You have mountains of valuable data, but getting clear answers feels impossible. The good news? The problem isn't your data; it's how that data is organized. This is exactly what the star schema data model is designed to fix—and it’s the secret to getting fast, reliable insights.
Your Data Has Answers, But You Can't Get to Them
You're sitting on a goldmine. All the information about customer behavior, sales trends, and marketing performance is locked away in your databases. But when you need a straightforward chart, it turns into a formal request that lands in a queue, sometimes for weeks.
This delay isn’t happening because your analysts are slow. It’s because the underlying data is a tangled mess. When data is scattered across dozens of tables with no intuitive structure, every single question requires a complex, custom-built SQL query. It's a manual process that’s not only slow but also ripe for errors—a huge bottleneck for any company that needs to move quickly.
The Problem Is Structure, Not Your Data
A star schema cuts through this chaos. Think of it as a clean, logical blueprint for your business metrics. Instead of a web of interconnected tables that only a handful of experts can navigate, you get a simple, star-shaped model that makes finding information incredibly efficient.
This model has become the go-to standard for analytics for a few key reasons:
Speed: It’s optimized for lightning-fast queries.
Clarity: The structure is simple enough for both BI tools and humans to easily understand.
Reliability: It establishes a single source of truth for your most important metrics, ensuring everyone is looking at the same numbers.
Better yet, this clean structure is precisely what tools like a Conversational AI Data Analyst need to function. With a star schema in place, a platform like Statspresso knows exactly where to find the data to answer your questions instantly.
You can finally skip the SQL. Just ask a question, and get a chart in seconds.
This guide will walk you through why this simple-yet-powerful concept is the key to unlocking instant, trustworthy answers. We'll show you how to move from data chaos to a clean, effective model that empowers your entire team to make decisions without waiting in line.
Try asking Statspresso: "Show me my revenue by month for the last year as a bar chart."
What Is a Star Schema Data Model?
If you want to get real answers from your data, you first need to organize it in a way that makes sense.That's where the star schema comes in—it's less a technical command and more a brilliantly simple blueprint for your analytics. To see the full landscape, it's worth knowing how it fits into the broader world of data modeling and its various types.
Think of a star schema like this: at the very center, you have a single table holding all your most important numbers. This is your fact table. It contains the raw, quantitative metrics you're obsessed with tracking, like sales_revenue, units_sold, or user_signups. These are the "what happened" figures.
The Star Points: Context Is Everything
Of course, numbers without context are meaningless. Radiating out from that central fact table are several dimension tables, which form the points of the star. These tables provide the crucial "who, what, where, and when" that give your facts meaning.
Each dimension table is dedicated to describing one business concept:
Customers: Who made the purchase?
Products: What exactly did they buy?
Locations: Where did this transaction take place?
Dates: When did it all happen?
This "hub-and-spoke" design is the star schema's superpower. When you need an answer, you simply connect the context from a dimension table (a spoke) to the numbers in the central fact table (the hub). This structure dramatically reduces the complex "joins" that slow traditional databases to a crawl, making your queries incredibly fast.
This isn't some new trend; the star schema has been a fundamental part of data warehousing since the 1990s. Its elegant simplicity is why it delivers lightning-fast queries, giving it a massive performance edge over more complicated models. That speed is more critical than ever, especially as AI-driven demands for quick data access continue to grow. You can find more on how the star schema compares to other models on Kanerika.com.
Why This Matters for You
So, why should a founder or product manager care about data architecture? Because a well-designed star schema is the bedrock of self-service analytics and a single source of truth everyone in the company can rely on.
Even more importantly, this clean structure is what enables a Conversational AI Data Analyst, like Statspresso, to understand your business. The AI can instantly see the relationship between customers and sales because the star schema acts as a clear, logical map. You just ask, and the AI follows the paths on the map to pull your answer.
Instead of waiting for a developer to write a complex SQL query, you simply connect the dots. It’s analytics at the speed of thought.
The difference in workflow is night and day. The old, manual process is a bottleneck; the new way is instantaneous.
Old Way (Manual SQL & Dashboards) | New Way (Statspresso & Star Schema) |
|---|---|
Wait days or weeks for a report | Get answers in seconds |
Relies on technical experts | Empowers anyone to ask questions |
Complex, error-prone queries | Direct, plain-English questions |
Static, quickly outdated reports | Real-time, interactive charts |
By organizing your data this way, you shift from being reactive to proactive. Your data stops being a frustrating roadblock and becomes your most powerful strategic asset.
The Building Blocks of a Star Schema
Alright, so you see the appeal of the star schema. But what are the actual moving parts? It's less complicated than you might imagine. A star schema is built from just two core components: fact tables and dimension tables.
Think of it like building with LEGOs. You have your core structural bricks and your specialized, descriptive pieces. Getting these two parts right is everything. In fact, knowing how to design database schema for scalable applications is a foundational skill for anyone building a data model that needs to stand the test of time and scale.
The Center of the Universe: The Fact Table
First, let's talk about the fact table. This is the sun in your solar system—the gravitational center holding everything together. It's where you store the quantitative pulse of your business: the raw numbers and metrics you track. Think sales_amount, units_sold, login_count, or ad_spend.
Essentially, these tables are just a running log of business events. Every time a customer completes a purchase or a user views a page, a new row is added to a fact table. The key thing to remember is that facts are numeric and measurable. You can add them, average them, or count them. You can't sum up customer names, but you can absolutely sum up their lifetime value.
This brings us to a crucial concept: granularity. The grain of your fact table defines the level of detail each row represents. Is a single row one transaction? One item within a transaction? Or a daily summary of all sales for a store?
Choosing the right grain is the single most important decision you'll make when designing a star schema. It dictates the kinds of questions you can answer. If your grain is "daily sales per store," you can never analyze sales by the hour.
The Points of the Star: Dimension Tables
A fact table full of numbers is pretty useless on its own. 100,000 means nothing without context. That’s where dimension tables shine. They are the descriptive tables that orbit your central fact table, providing the all-important "who, what, where, when, and why" behind your metrics.
Some classic examples of dimension tables include:
dim_Customers: Who made the purchase? This table holds customer names, locations, segments, and sign-up dates.
dim_Products: What was purchased? Here you'll find the product name, category, brand, color, and size.
dim_Date: When did it happen? This is a special but essential table that breaks down dates into useful attributes like year, quarter, month, day of the week, and holiday flags for powerful time-based analysis.
This simple diagram perfectly captures the relationship. The central fact table gives you the numbers, and the surrounding dimension tables tell you the story behind them.
As you can see, you get answers by connecting the context (the Who, What, Where) to the core events (the Facts). This structure makes slicing and dicing your data incredibly intuitive.
The Glue That Holds It Together: Keys
So how do we physically link the fct_Sales table to the dim_Products table? We use keys. Keys are just special columns that serve as unique identifiers, forming the connective tissue between your facts and dimensions.
In the world of data modeling, you'll mainly encounter two types of keys:
Natural Keys: These are identifiers that already exist in your operational systems. Think of a product's SKU, a user's email address, or a government ID number. They seem convenient at first but can be a trap. What happens when an email changes or a SKU is recycled? Chaos.
Surrogate Keys: These are clean, system-generated integers (e.g., 1, 2, 3...) that have no business meaning whatsoever. Their only job is to uniquely identify a row in a dimension table within the data warehouse.
When it comes to analytics, surrogate keys are almost always the better choice. They’re stable even when business attributes change, they're small, and they make the joins between your potentially massive fact table and your dimensions incredibly fast. This is the kind of clean, efficient design that allows a Conversational AI Data Analyst like Statspresso to zip through your data and find answers in seconds.
Star Schema vs. Snowflake Schema: A Quick Comparison
If you've spent any time around data warehouses, you've probably heard the term "snowflake schema" pop up. It’s often mentioned in the same breath as the star schema, but don't be fooled—the two models are built for very different purposes, and choosing the wrong one can bring your analytics to a grinding halt.
At their core, the difference comes down to one concept: denormalization. A star schema embraces it. It keeps all the related details for a business concept—like a product's name, its category, and its brand—together in a single, wide dimension table. It’s simple and straightforward.
A snowflake schema does the opposite. It normalizes those dimensions, breaking them out into a web of smaller, interconnected tables. You might have a product table that links to a separate category table, which then links to yet another sub-category table. This creates a structure with many intricate, branching points, much like a snowflake.
It All Comes Down to Performance
The main argument for the snowflake schema is that it can save a little bit of storage space by reducing redundant data. While true in theory, this tiny bit of savings comes at a massive cost: query performance.
Every extra table in a snowflake schema adds another JOIN operation to your query. More joins mean more work for the database, which leads to slower queries. For anyone who needs to make decisions quickly, waiting minutes for a dashboard to load simply isn't an option. The star schema’s flat, simple structure is built for speed, making it the clear winner for modern analytics.
For the vast majority of BI and analytics tasks—we’re talking over 90% of cases—the star schema’s incredible speed and simplicity make it the superior choice.
Star Schema vs. Snowflake Schema: Which Is Right for You?
While snowflake schemas still have a place in some highly specialized, transaction-heavy enterprise systems, the star schema is almost always the right answer for fast, reliable analytics. Let's put them side-by-side to see why. This table compares the two popular data modeling schemas across key attributes to help you decide which is better for your analytics needs.
Attribute | Star Schema (Optimized for Speed) | Snowflake Schema (Optimized for Storage) |
|---|---|---|
Query Speed | Lightning-fast. Fewer joins mean queries run in a fraction of the time, keeping dashboards responsive. | Slower. Requires multiple, complex joins that can easily bog down performance. |
Complexity | Low. The model is intuitive and easy for both humans and BI tools to understand and navigate. | High. The web of interconnected tables is confusing for anyone who isn't a data engineer. |
Ease of Use | Effortless. The simple structure is ideal for BI tools and AI assistants that need to interpret the data. | Difficult. Writing SQL is more complex, and business users will struggle to make sense of the model. |
Maintenance | Simpler to manage. The straightforward design is easier to troubleshoot and maintain as a single source of truth. | More complex to maintain. While updating a single attribute is easy, managing the entire structure is not. |
For most modern BI and AI analytics, the star schema's performance is superior. The decision really hinges on what you value most: a small amount of storage efficiency or real-world, practical speed. The star schema is purpose-built to get you answers fast. It’s the pragmatic choice for teams that need to move quickly and make decisions with fresh data, not wait around for a complex query to finish.
This focus on speed is exactly why tools like Statspresso are designed to work seamlessly with star schemas.
Try asking Statspresso: "Compare our top 5 products by total sales this quarter."
Why Conversational AI Loves the Star Schema
So, why does the star schema get so much attention? It's pretty straightforward: this particular data model is the backbone that allows modern analytics tools to deliver answers so quickly. More to the point, it’s what lets a Conversational AI Data Analyst like Statspresso respond to your questions in seconds, not weeks.
The star schema’s popularity isn't an accident; it’s a direct result of its effectiveness. It has become a de-facto standard for a reason. And with Gartner predicting that by 2026, 70% of organizations will focus on business outcomes by adopting vertically integrated data stacks, the need for a simple, fast, and understandable data model like the star schema will only grow. This widespread adoption means that no matter what tool you're using—Tableau, Power BI, or a next-generation platform—the system can intuitively understand your data’s layout. You can explore the full research on modern data trends to see how it fits into the broader landscape.
Eliminating Ambiguity for the AI
Think about onboarding a new analyst. If you just pointed them to a messy collection of spreadsheets and asked for a sales comparison, they’d immediately have questions. "Which sales numbers? For what time period? How do I connect products to regions?" An AI runs into the exact same wall of confusion.
The star schema gets rid of all that ambiguity by providing a clean, pre-defined map of your business logic.
Facts are unmistakable: The AI knows that the
fct_salestable holds your core quantitative metrics, like revenue or units sold.Dimensions add context: It sees
dim_productanddim_regionand instantly grasps that these tables describe the "what" and "where" behind the numbers.Relationships are crystal clear: The keys connecting the tables act like well-lit signposts, telling the AI exactly how to join sales events with the products sold and the regions they were sold in.
So when you ask a question like, "Compare sales for Product A and Product B by region this quarter," the AI isn't left to guess. It’s simply following the logical pathways you’ve already built into the model.
A star schema transforms a complex guessing game into a simple game of connect-the-dots. The AI doesn’t have to waste processing power figuring out your data's structure; it can get straight to calculating the answer.
The Power of Speed and Simplicity
The real magic happens when you pair this predictable structure with a powerful conversational AI engine. The star schema provides the clean, high-octane fuel, and the AI acts as the high-performance engine that runs on it.
This is exactly why you can skip writing SQL and just ask your data a question. Behind the scenes, the AI translates your plain-English request into an incredibly efficient SQL query. Because the star schema’s structure is so logical, the resulting query is simple, with very few joins needed to get the job done fast.
This stands in stark contrast to a snowflake schema, which can slow down queries by 2-5x due to the chain of extra joins required to piece together information. For the dashboards and self-serve reports that inform an estimated 80% of business decisions, the star schema’s speed is a crucial advantage.
Let's look at how this changes the day-to-day workflow.
The Old Way (Manual SQL & Traditional BI) | The New Way (Statspresso & Star Schema) |
|---|---|
Your question becomes a ticket in a backlog. | You ask your question directly in plain English. |
An analyst deciphers a messy data structure. | The AI instantly maps your words to facts and dimensions. |
They write a complex, multi-join SQL query. | The AI generates a simple, optimized SQL query. |
You get a static report back days or weeks later. | You get an interactive chart back in seconds. |
This partnership between a well-designed star schema data model and a conversational platform creates true self-service analytics. It finally closes the gap between having data and actually being able to use it. The growth of AI-powered business intelligence is built on this very foundation.
Try asking Statspresso: "Show me my top 10 customers by lifetime value as a horizontal bar chart."
Key Takeaways: Your Star Schema Cheat Sheet
You're busy. Here's the TL;DR on the star schema data model so you can get back to building your business.
It’s a Blueprint for Speed: The star schema organizes your data for one thing: fast, simple queries.
Facts in the Middle, Context on the Sides: It uses a central fact table for your numbers (like revenue) and surrounding dimension tables for context (like customers, products, and dates).
Fewer Joins = Faster Answers: The flat structure avoids the complex, multi-step queries that slow down other models, making it ideal for analytics.
The AI's Best Friend: This clear, logical layout is exactly what a Conversational AI Data Analyst like Statspresso needs to understand your data and answer questions instantly.
The Goal is Self-Service: The ultimate benefit is empowering your whole team to skip the SQL, ask questions in plain English, and get charts in seconds.
Frequently Asked Questions
Do I Need to Be a Data Engineer to Build a Star Schema?
Not like you used to. While a data engineer is still the best person for a massive, enterprise-wide implementation, modern tools have made star schemas much more accessible.
Platforms like dbt (data build tool) let analysts with some SQL knowledge transform raw data from sources like Postgres or Shopify into clean star schemas. And for those who aren't technical, a conversational AI platform like Statspresso works best with a star schema, but it's often smart enough to make sense of less-structured data, too.
Can I Use a Star Schema with Real-Time Data?
Absolutely, though with a couple of things to keep in mind. Star schemas earned their reputation in data warehouses that were updated in batches overnight. But today, they work perfectly well for near real-time analytics.
Modern cloud data warehouses like Snowflake or BigQuery and new streaming technologies let you update your fact tables in tiny, frequent micro-batches. For most business questions, a few minutes of delay is perfectly fine, and the sheer query speed of the star schema makes it the right choice.
Try asking Statspresso: "Show me our sales from the last hour, broken down by product category."
How Many Dimension Tables Are Too Many?
There isn't a magic number. A typical star schema data model might have anywhere from five to fifteen dimension tables. The real question to ask yourself is: what context do I need for my analysis?
If you need to slice your key numbers by a business concept—like a customer segment, a marketing campaign, or a sales region—then it probably deserves its own dimension table. The goal isn't to hit a certain number; it's to keep the model simple and clear so you can get fast, intuitive answers.
Ready to stop waiting for reports and start getting answers? With Statspresso, you can skip the SQL and the dashboard queues. Just ask your data a question and get a chart in seconds.
Connect your first data source for free and ask your first question.
Waiting weeks for a data analyst to build a simple dashboard is a relic of the past. You have mountains of valuable data, but getting clear answers feels impossible. The good news? The problem isn't your data; it's how that data is organized. This is exactly what the star schema data model is designed to fix—and it’s the secret to getting fast, reliable insights.
Your Data Has Answers, But You Can't Get to Them
You're sitting on a goldmine. All the information about customer behavior, sales trends, and marketing performance is locked away in your databases. But when you need a straightforward chart, it turns into a formal request that lands in a queue, sometimes for weeks.
This delay isn’t happening because your analysts are slow. It’s because the underlying data is a tangled mess. When data is scattered across dozens of tables with no intuitive structure, every single question requires a complex, custom-built SQL query. It's a manual process that’s not only slow but also ripe for errors—a huge bottleneck for any company that needs to move quickly.
The Problem Is Structure, Not Your Data
A star schema cuts through this chaos. Think of it as a clean, logical blueprint for your business metrics. Instead of a web of interconnected tables that only a handful of experts can navigate, you get a simple, star-shaped model that makes finding information incredibly efficient.
This model has become the go-to standard for analytics for a few key reasons:
Speed: It’s optimized for lightning-fast queries.
Clarity: The structure is simple enough for both BI tools and humans to easily understand.
Reliability: It establishes a single source of truth for your most important metrics, ensuring everyone is looking at the same numbers.
Better yet, this clean structure is precisely what tools like a Conversational AI Data Analyst need to function. With a star schema in place, a platform like Statspresso knows exactly where to find the data to answer your questions instantly.
You can finally skip the SQL. Just ask a question, and get a chart in seconds.
This guide will walk you through why this simple-yet-powerful concept is the key to unlocking instant, trustworthy answers. We'll show you how to move from data chaos to a clean, effective model that empowers your entire team to make decisions without waiting in line.
Try asking Statspresso: "Show me my revenue by month for the last year as a bar chart."
What Is a Star Schema Data Model?
If you want to get real answers from your data, you first need to organize it in a way that makes sense.That's where the star schema comes in—it's less a technical command and more a brilliantly simple blueprint for your analytics. To see the full landscape, it's worth knowing how it fits into the broader world of data modeling and its various types.
Think of a star schema like this: at the very center, you have a single table holding all your most important numbers. This is your fact table. It contains the raw, quantitative metrics you're obsessed with tracking, like sales_revenue, units_sold, or user_signups. These are the "what happened" figures.
The Star Points: Context Is Everything
Of course, numbers without context are meaningless. Radiating out from that central fact table are several dimension tables, which form the points of the star. These tables provide the crucial "who, what, where, and when" that give your facts meaning.
Each dimension table is dedicated to describing one business concept:
Customers: Who made the purchase?
Products: What exactly did they buy?
Locations: Where did this transaction take place?
Dates: When did it all happen?
This "hub-and-spoke" design is the star schema's superpower. When you need an answer, you simply connect the context from a dimension table (a spoke) to the numbers in the central fact table (the hub). This structure dramatically reduces the complex "joins" that slow traditional databases to a crawl, making your queries incredibly fast.
This isn't some new trend; the star schema has been a fundamental part of data warehousing since the 1990s. Its elegant simplicity is why it delivers lightning-fast queries, giving it a massive performance edge over more complicated models. That speed is more critical than ever, especially as AI-driven demands for quick data access continue to grow. You can find more on how the star schema compares to other models on Kanerika.com.
Why This Matters for You
So, why should a founder or product manager care about data architecture? Because a well-designed star schema is the bedrock of self-service analytics and a single source of truth everyone in the company can rely on.
Even more importantly, this clean structure is what enables a Conversational AI Data Analyst, like Statspresso, to understand your business. The AI can instantly see the relationship between customers and sales because the star schema acts as a clear, logical map. You just ask, and the AI follows the paths on the map to pull your answer.
Instead of waiting for a developer to write a complex SQL query, you simply connect the dots. It’s analytics at the speed of thought.
The difference in workflow is night and day. The old, manual process is a bottleneck; the new way is instantaneous.
Old Way (Manual SQL & Dashboards) | New Way (Statspresso & Star Schema) |
|---|---|
Wait days or weeks for a report | Get answers in seconds |
Relies on technical experts | Empowers anyone to ask questions |
Complex, error-prone queries | Direct, plain-English questions |
Static, quickly outdated reports | Real-time, interactive charts |
By organizing your data this way, you shift from being reactive to proactive. Your data stops being a frustrating roadblock and becomes your most powerful strategic asset.
The Building Blocks of a Star Schema
Alright, so you see the appeal of the star schema. But what are the actual moving parts? It's less complicated than you might imagine. A star schema is built from just two core components: fact tables and dimension tables.
Think of it like building with LEGOs. You have your core structural bricks and your specialized, descriptive pieces. Getting these two parts right is everything. In fact, knowing how to design database schema for scalable applications is a foundational skill for anyone building a data model that needs to stand the test of time and scale.
The Center of the Universe: The Fact Table
First, let's talk about the fact table. This is the sun in your solar system—the gravitational center holding everything together. It's where you store the quantitative pulse of your business: the raw numbers and metrics you track. Think sales_amount, units_sold, login_count, or ad_spend.
Essentially, these tables are just a running log of business events. Every time a customer completes a purchase or a user views a page, a new row is added to a fact table. The key thing to remember is that facts are numeric and measurable. You can add them, average them, or count them. You can't sum up customer names, but you can absolutely sum up their lifetime value.
This brings us to a crucial concept: granularity. The grain of your fact table defines the level of detail each row represents. Is a single row one transaction? One item within a transaction? Or a daily summary of all sales for a store?
Choosing the right grain is the single most important decision you'll make when designing a star schema. It dictates the kinds of questions you can answer. If your grain is "daily sales per store," you can never analyze sales by the hour.
The Points of the Star: Dimension Tables
A fact table full of numbers is pretty useless on its own. 100,000 means nothing without context. That’s where dimension tables shine. They are the descriptive tables that orbit your central fact table, providing the all-important "who, what, where, when, and why" behind your metrics.
Some classic examples of dimension tables include:
dim_Customers: Who made the purchase? This table holds customer names, locations, segments, and sign-up dates.
dim_Products: What was purchased? Here you'll find the product name, category, brand, color, and size.
dim_Date: When did it happen? This is a special but essential table that breaks down dates into useful attributes like year, quarter, month, day of the week, and holiday flags for powerful time-based analysis.
This simple diagram perfectly captures the relationship. The central fact table gives you the numbers, and the surrounding dimension tables tell you the story behind them.
As you can see, you get answers by connecting the context (the Who, What, Where) to the core events (the Facts). This structure makes slicing and dicing your data incredibly intuitive.
The Glue That Holds It Together: Keys
So how do we physically link the fct_Sales table to the dim_Products table? We use keys. Keys are just special columns that serve as unique identifiers, forming the connective tissue between your facts and dimensions.
In the world of data modeling, you'll mainly encounter two types of keys:
Natural Keys: These are identifiers that already exist in your operational systems. Think of a product's SKU, a user's email address, or a government ID number. They seem convenient at first but can be a trap. What happens when an email changes or a SKU is recycled? Chaos.
Surrogate Keys: These are clean, system-generated integers (e.g., 1, 2, 3...) that have no business meaning whatsoever. Their only job is to uniquely identify a row in a dimension table within the data warehouse.
When it comes to analytics, surrogate keys are almost always the better choice. They’re stable even when business attributes change, they're small, and they make the joins between your potentially massive fact table and your dimensions incredibly fast. This is the kind of clean, efficient design that allows a Conversational AI Data Analyst like Statspresso to zip through your data and find answers in seconds.
Star Schema vs. Snowflake Schema: A Quick Comparison
If you've spent any time around data warehouses, you've probably heard the term "snowflake schema" pop up. It’s often mentioned in the same breath as the star schema, but don't be fooled—the two models are built for very different purposes, and choosing the wrong one can bring your analytics to a grinding halt.
At their core, the difference comes down to one concept: denormalization. A star schema embraces it. It keeps all the related details for a business concept—like a product's name, its category, and its brand—together in a single, wide dimension table. It’s simple and straightforward.
A snowflake schema does the opposite. It normalizes those dimensions, breaking them out into a web of smaller, interconnected tables. You might have a product table that links to a separate category table, which then links to yet another sub-category table. This creates a structure with many intricate, branching points, much like a snowflake.
It All Comes Down to Performance
The main argument for the snowflake schema is that it can save a little bit of storage space by reducing redundant data. While true in theory, this tiny bit of savings comes at a massive cost: query performance.
Every extra table in a snowflake schema adds another JOIN operation to your query. More joins mean more work for the database, which leads to slower queries. For anyone who needs to make decisions quickly, waiting minutes for a dashboard to load simply isn't an option. The star schema’s flat, simple structure is built for speed, making it the clear winner for modern analytics.
For the vast majority of BI and analytics tasks—we’re talking over 90% of cases—the star schema’s incredible speed and simplicity make it the superior choice.
Star Schema vs. Snowflake Schema: Which Is Right for You?
While snowflake schemas still have a place in some highly specialized, transaction-heavy enterprise systems, the star schema is almost always the right answer for fast, reliable analytics. Let's put them side-by-side to see why. This table compares the two popular data modeling schemas across key attributes to help you decide which is better for your analytics needs.
Attribute | Star Schema (Optimized for Speed) | Snowflake Schema (Optimized for Storage) |
|---|---|---|
Query Speed | Lightning-fast. Fewer joins mean queries run in a fraction of the time, keeping dashboards responsive. | Slower. Requires multiple, complex joins that can easily bog down performance. |
Complexity | Low. The model is intuitive and easy for both humans and BI tools to understand and navigate. | High. The web of interconnected tables is confusing for anyone who isn't a data engineer. |
Ease of Use | Effortless. The simple structure is ideal for BI tools and AI assistants that need to interpret the data. | Difficult. Writing SQL is more complex, and business users will struggle to make sense of the model. |
Maintenance | Simpler to manage. The straightforward design is easier to troubleshoot and maintain as a single source of truth. | More complex to maintain. While updating a single attribute is easy, managing the entire structure is not. |
For most modern BI and AI analytics, the star schema's performance is superior. The decision really hinges on what you value most: a small amount of storage efficiency or real-world, practical speed. The star schema is purpose-built to get you answers fast. It’s the pragmatic choice for teams that need to move quickly and make decisions with fresh data, not wait around for a complex query to finish.
This focus on speed is exactly why tools like Statspresso are designed to work seamlessly with star schemas.
Try asking Statspresso: "Compare our top 5 products by total sales this quarter."
Why Conversational AI Loves the Star Schema
So, why does the star schema get so much attention? It's pretty straightforward: this particular data model is the backbone that allows modern analytics tools to deliver answers so quickly. More to the point, it’s what lets a Conversational AI Data Analyst like Statspresso respond to your questions in seconds, not weeks.
The star schema’s popularity isn't an accident; it’s a direct result of its effectiveness. It has become a de-facto standard for a reason. And with Gartner predicting that by 2026, 70% of organizations will focus on business outcomes by adopting vertically integrated data stacks, the need for a simple, fast, and understandable data model like the star schema will only grow. This widespread adoption means that no matter what tool you're using—Tableau, Power BI, or a next-generation platform—the system can intuitively understand your data’s layout. You can explore the full research on modern data trends to see how it fits into the broader landscape.
Eliminating Ambiguity for the AI
Think about onboarding a new analyst. If you just pointed them to a messy collection of spreadsheets and asked for a sales comparison, they’d immediately have questions. "Which sales numbers? For what time period? How do I connect products to regions?" An AI runs into the exact same wall of confusion.
The star schema gets rid of all that ambiguity by providing a clean, pre-defined map of your business logic.
Facts are unmistakable: The AI knows that the
fct_salestable holds your core quantitative metrics, like revenue or units sold.Dimensions add context: It sees
dim_productanddim_regionand instantly grasps that these tables describe the "what" and "where" behind the numbers.Relationships are crystal clear: The keys connecting the tables act like well-lit signposts, telling the AI exactly how to join sales events with the products sold and the regions they were sold in.
So when you ask a question like, "Compare sales for Product A and Product B by region this quarter," the AI isn't left to guess. It’s simply following the logical pathways you’ve already built into the model.
A star schema transforms a complex guessing game into a simple game of connect-the-dots. The AI doesn’t have to waste processing power figuring out your data's structure; it can get straight to calculating the answer.
The Power of Speed and Simplicity
The real magic happens when you pair this predictable structure with a powerful conversational AI engine. The star schema provides the clean, high-octane fuel, and the AI acts as the high-performance engine that runs on it.
This is exactly why you can skip writing SQL and just ask your data a question. Behind the scenes, the AI translates your plain-English request into an incredibly efficient SQL query. Because the star schema’s structure is so logical, the resulting query is simple, with very few joins needed to get the job done fast.
This stands in stark contrast to a snowflake schema, which can slow down queries by 2-5x due to the chain of extra joins required to piece together information. For the dashboards and self-serve reports that inform an estimated 80% of business decisions, the star schema’s speed is a crucial advantage.
Let's look at how this changes the day-to-day workflow.
The Old Way (Manual SQL & Traditional BI) | The New Way (Statspresso & Star Schema) |
|---|---|
Your question becomes a ticket in a backlog. | You ask your question directly in plain English. |
An analyst deciphers a messy data structure. | The AI instantly maps your words to facts and dimensions. |
They write a complex, multi-join SQL query. | The AI generates a simple, optimized SQL query. |
You get a static report back days or weeks later. | You get an interactive chart back in seconds. |
This partnership between a well-designed star schema data model and a conversational platform creates true self-service analytics. It finally closes the gap between having data and actually being able to use it. The growth of AI-powered business intelligence is built on this very foundation.
Try asking Statspresso: "Show me my top 10 customers by lifetime value as a horizontal bar chart."
Key Takeaways: Your Star Schema Cheat Sheet
You're busy. Here's the TL;DR on the star schema data model so you can get back to building your business.
It’s a Blueprint for Speed: The star schema organizes your data for one thing: fast, simple queries.
Facts in the Middle, Context on the Sides: It uses a central fact table for your numbers (like revenue) and surrounding dimension tables for context (like customers, products, and dates).
Fewer Joins = Faster Answers: The flat structure avoids the complex, multi-step queries that slow down other models, making it ideal for analytics.
The AI's Best Friend: This clear, logical layout is exactly what a Conversational AI Data Analyst like Statspresso needs to understand your data and answer questions instantly.
The Goal is Self-Service: The ultimate benefit is empowering your whole team to skip the SQL, ask questions in plain English, and get charts in seconds.
Frequently Asked Questions
Do I Need to Be a Data Engineer to Build a Star Schema?
Not like you used to. While a data engineer is still the best person for a massive, enterprise-wide implementation, modern tools have made star schemas much more accessible.
Platforms like dbt (data build tool) let analysts with some SQL knowledge transform raw data from sources like Postgres or Shopify into clean star schemas. And for those who aren't technical, a conversational AI platform like Statspresso works best with a star schema, but it's often smart enough to make sense of less-structured data, too.
Can I Use a Star Schema with Real-Time Data?
Absolutely, though with a couple of things to keep in mind. Star schemas earned their reputation in data warehouses that were updated in batches overnight. But today, they work perfectly well for near real-time analytics.
Modern cloud data warehouses like Snowflake or BigQuery and new streaming technologies let you update your fact tables in tiny, frequent micro-batches. For most business questions, a few minutes of delay is perfectly fine, and the sheer query speed of the star schema makes it the right choice.
Try asking Statspresso: "Show me our sales from the last hour, broken down by product category."
How Many Dimension Tables Are Too Many?
There isn't a magic number. A typical star schema data model might have anywhere from five to fifteen dimension tables. The real question to ask yourself is: what context do I need for my analysis?
If you need to slice your key numbers by a business concept—like a customer segment, a marketing campaign, or a sales region—then it probably deserves its own dimension table. The goal isn't to hit a certain number; it's to keep the model simple and clear so you can get fast, intuitive answers.
Ready to stop waiting for reports and start getting answers? With Statspresso, you can skip the SQL and the dashboard queues. Just ask your data a question and get a chart in seconds.
Connect your first data source for free and ask your first question.